# Attaching packages: easystats 0.6.0 (red = needs update)
✖ bayestestR 0.13.1 ✖ correlation 0.8.4
✖ datawizard 0.8.0 ✖ effectsize 0.8.3
✖ insight 0.19.7 ✖ modelbased 0.8.6
✖ performance 0.10.4 ✖ parameters 0.21.1
✖ report 0.5.7 ✖ see 0.8.0
Restart the R-Session and update packages in red with `easystats::easystats_update()`.
library(effectsize)
Read data
Let’s read the data from an URL (online) using the tidyverse function read_csv.
data <-read_csv("https://raw.githubusercontent.com/mario-bermonti/talks/refs/heads/main/intro_r_cognition/data.csv")
Rows: 100 Columns: 4
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): id, group
dbl (2): digit_span_forward, digit_span_backward
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Inspect the data
The first step when we get data is to inspect it to understand its structure and content.
We will examine the effect of Major Depressive Disorder (MDD) on the digit span forward task.
We will begin by visualizing the data, then we will calculate descriptive statistics, and finally, we will perform inferential statistics.
Viz
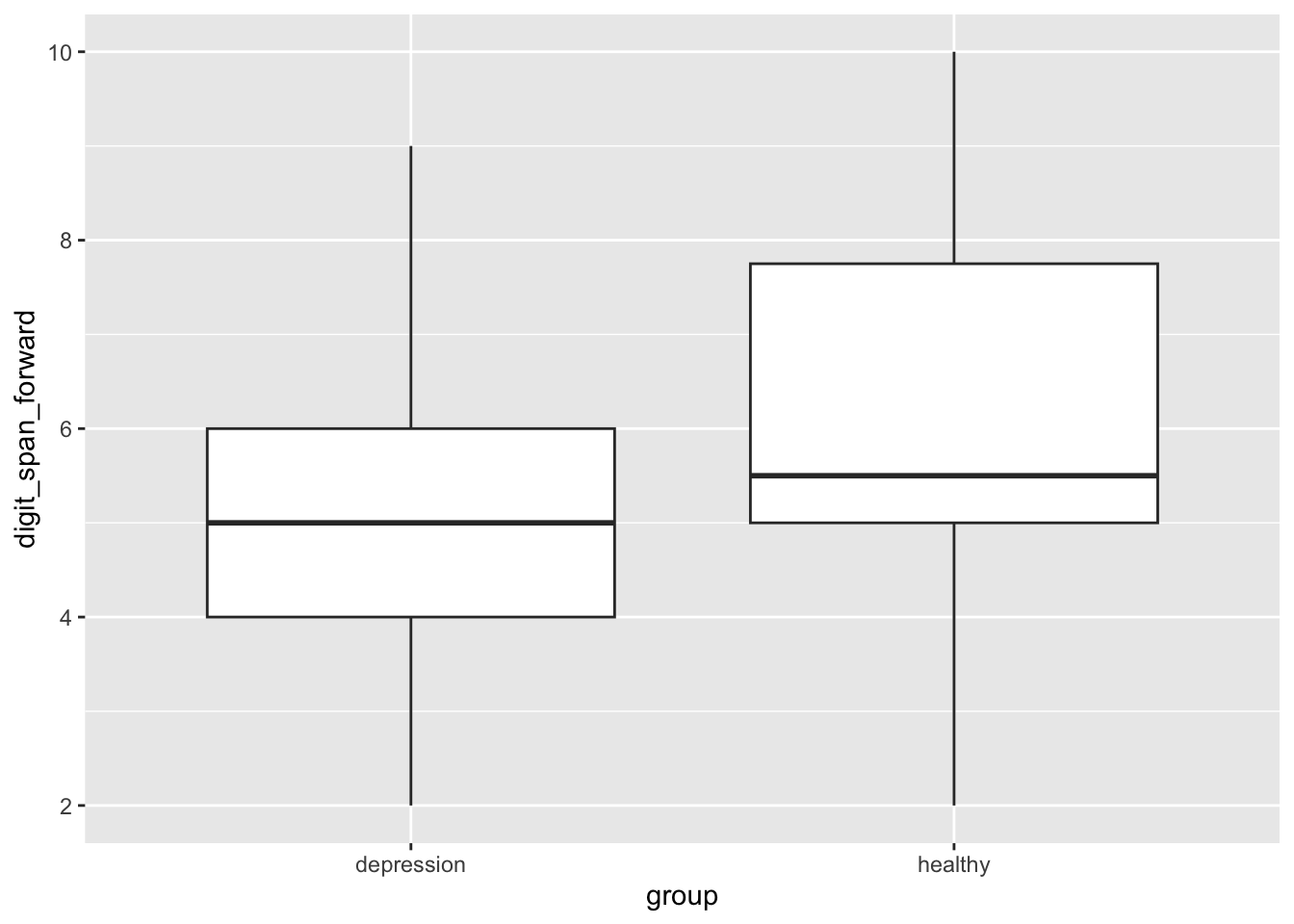
Box plot
We will start by creating a box plot to visualize the data.
We will use ggplot2 to create the plot. This is one of the most popular packages for data visualization in R.
Plots with ggplot2 are built in layers, where each layer adds elements on top of the previous one. We add these layers using +, which is great it is an intuitive math operation.
ggplot( data,aes(x = group, y = digit_span_forward)) +geom_boxplot()
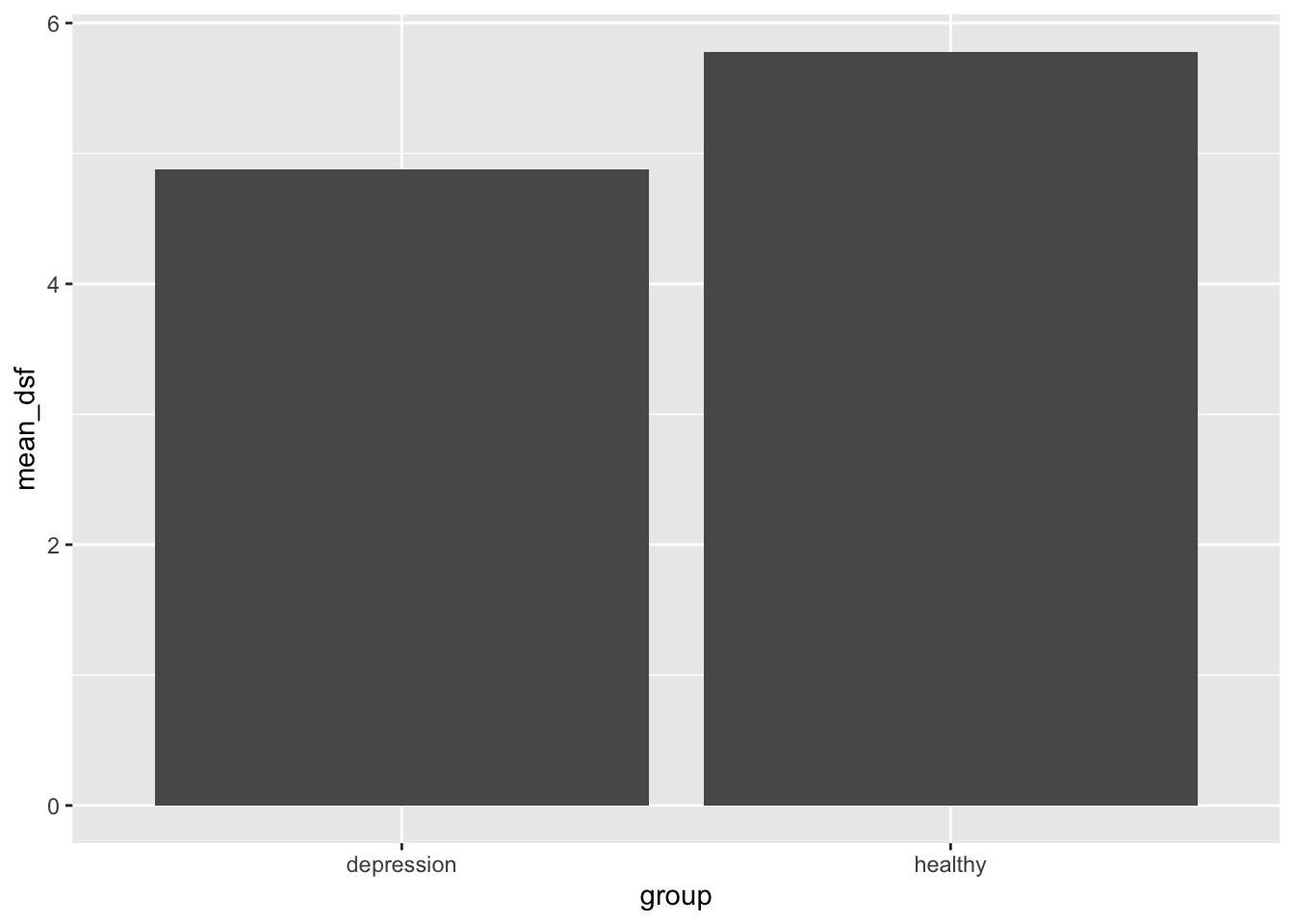
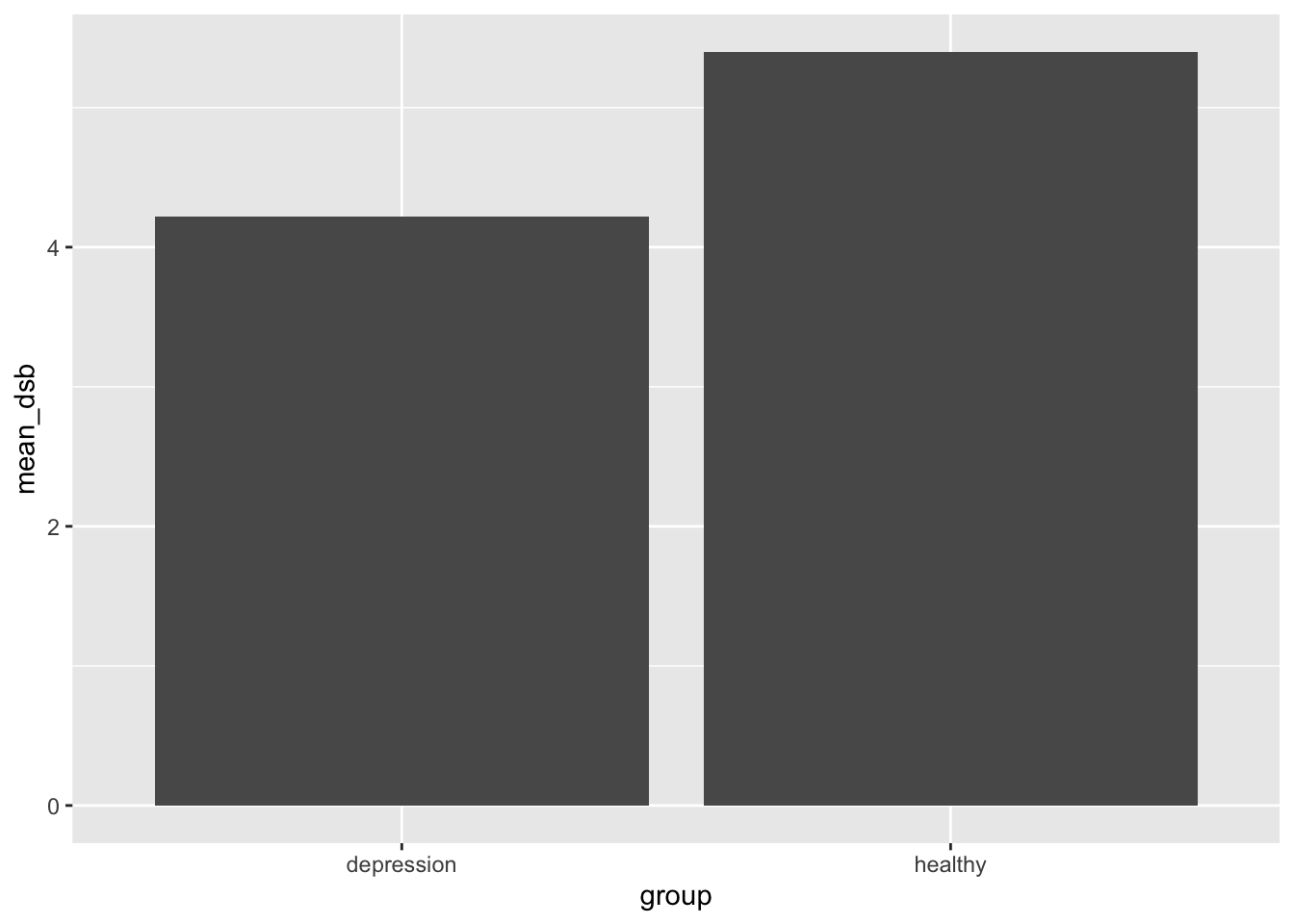
Bar plot
Bar plots are a little bit different and require us to calculate the mean before plotting.
Let’s calculate the means we will plot.
Notice that we are now using a |> symbol. This is a convenient way to perform multiple sequential operations on data since you “chain” these operations with |> (pipe operator). You should read it as:
“do operation 1”
“and then (|>)”
“do operation 2”
If you think about it is a natural way to express the steps below:
take the data
and then group it by the group variable
and then calculate the mean of the digit_span_forward variable
and then calculate the mean of the digit_span_backward variable
means <- data |>group_by(group) |>summarise(mean_dsf =mean(digit_span_forward),mean_dsb =mean(digit_span_backward) )means
group
mean_dsf
mean_dsb
depression
4.88
4.22
healthy
5.78
5.40
Now, let’s build the bar plot
ggplot(data = means,aes(x = group, y = mean_dsf)) +geom_bar(stat ="identity")
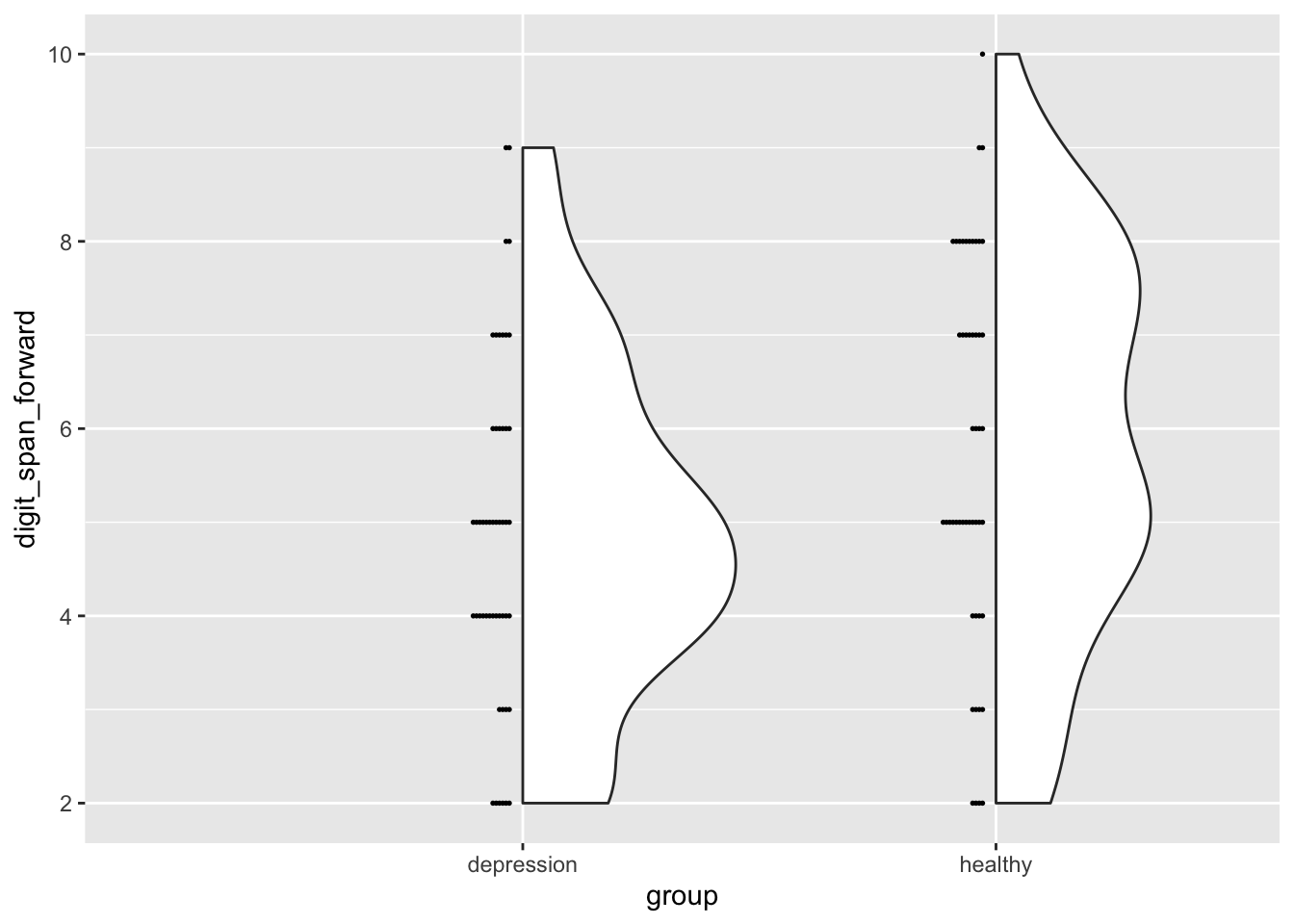
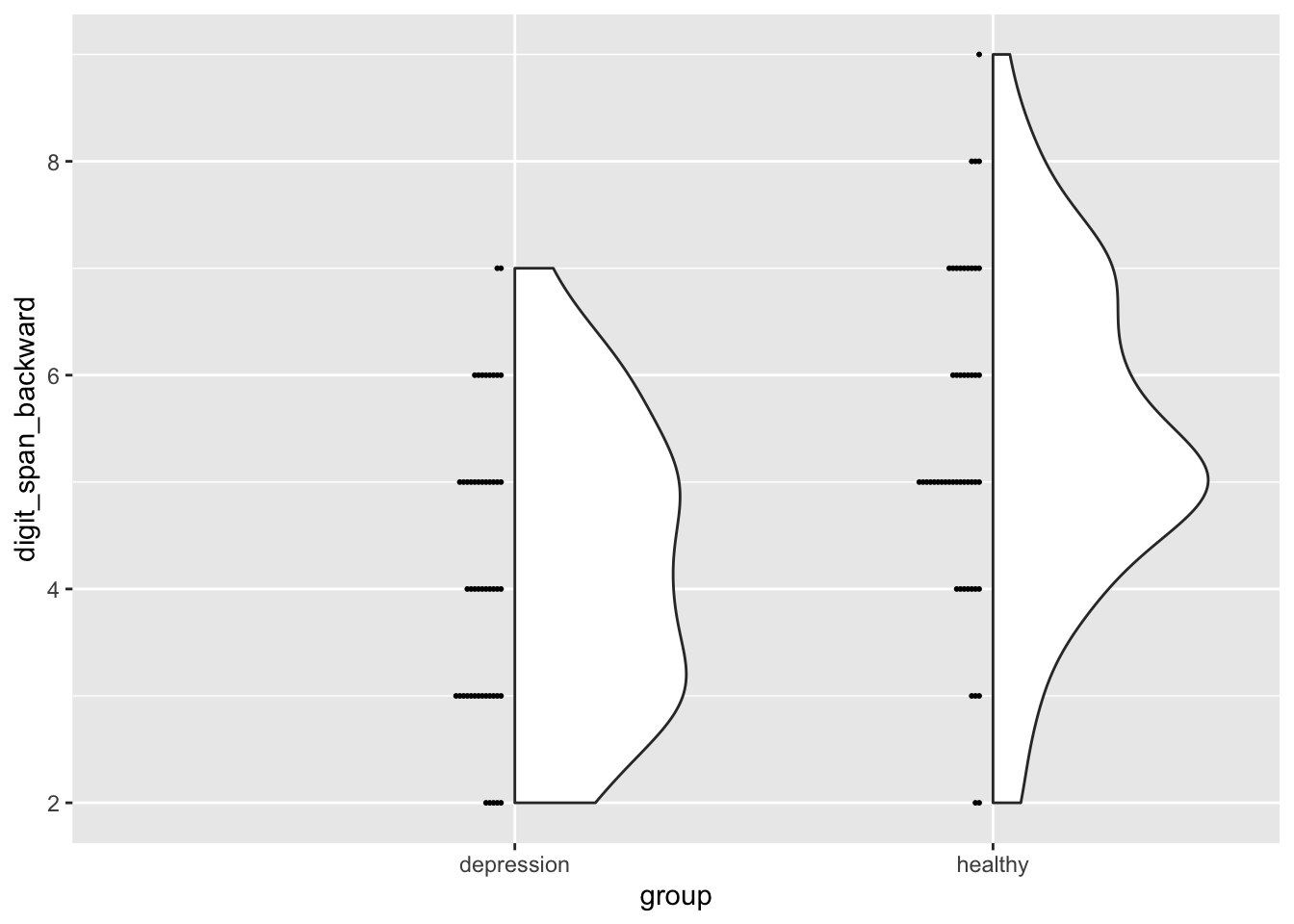
Violin plot
One great thing about R is that it can create all sort of beautiful and informative plots.
Violin and dot plots are great ways to visualize the distribution of the data. We will combine them into a single plot by combining ggplot2 and easystats’s see package.
ggplot( data,aes(x = group, y = digit_span_forward)) +geom_violindot()
Descriptive stats
As we know, summarizing the data is a crucial step in data analysis. It helps us understand the data by identifying patterns, checking for errors, and assumptions.
Let’s calculate the mean, standard deviation, minimum, and maximum of the digit_span_forward variable.
This is easily achieved in R using tidyverse’s summarise function.
General
Let’s first summarize the data without considering the groups.
data |>summarise(mean_dsf =mean(digit_span_forward),sd_dsf =sd(digit_span_forward),min_dsf =min(digit_span_forward),max_dsf =max(digit_span_forward) )
mean_dsf
sd_dsf
min_dsf
max_dsf
5.33
1.98507
2
10
By group
Now, let’s summarize the data for each group to allow group comparisons.
data |>group_by(group) |>summarise(mean_dsf =mean(digit_span_forward),sd_dsf =sd(digit_span_forward),min_dsf =min(digit_span_forward),max_dsf =max(digit_span_forward) )
group
mean_dsf
sd_dsf
min_dsf
max_dsf
depression
4.88
1.814229
2
9
healthy
5.78
2.063186
2
10
Inferential
Now that we understand the data better, we can perform inferential statistics to test if the differences we observed are statistically significant.
We will use a t-test because we are comparing the means of two groups.
R provides the t.test function which performs a t-test. Be mindful about the formula syntax used to specify the predictor and outcome.
The final bit tidy formats the results as a nice table.